

关于数据库基础入门,UNSW有两门课。本科的 COMP3311 和研究生的 COMP9311,这里主要按照 9311 目录整理内容,也参考了 3311 的部分。
| Week | Content |
|---|---|
| 1 | Intro to DB Conceptual DB Design |
| 2 | Relational Data Model Relational Algebra |
| 3 | SQL |
| 4 | PLpgSQL |
| 5 | Functional Dependencies Normal Forms |
| 6 | Quiet week |
| 7 | Relational Database Design Disk, File, Index |
| 8 | Transaction Management |
| 9 | NoSQL |
| 10 | Advanced Topics |
Week1.1
我们会学数据库的理论和操作,实体关系模型(ER Model),SQL,PostgreSQL, 但不包括数据库的实现(COMP9315)。
在学习过程中,谷歌搜索答案优于直接让ChatGPT返回结果。
在真实场景,数据需要被存储,访问,同时被多个用户分享和传输。前三者由数据库完成,传输由网络完成。数据有两大类:非结构化数据(Unstructured)和结构化数据。
使用文件系统管理数据的缺点:数据冗余,不一致,难以让多个用户同时访问。关系型数据库解决上述问题。日常使用例子包括:银行交易,航班管理,学校注册,零售管理,线上电商,制造业,人力管理。
数据库管理员(Database Administrator)的职责:Design of the conceptual and physical schemas,Security and authorization, Data availability and recovery from failures,Implement the specific requirements, Database tuning
点击这里查看最流行数据库排行。
数据模型的概念包括:Schema (类似定义的对象)Instance(实例),工作流程是指定 Schema 的数据来创建实例,通过加载数据初始化实例,随后更新修改操作实例。
数据建模(Data Modeling)是描述实体(entities)之间的关系,由此产生ER图 (Entity Relationship Diagram),此外实体还有各种属性(attributes),比如学生这个实体,学号是学生的属性。属性类型包括 Simple,Multi-Valued(比如描述校服的多种颜色),Composite(比如可以拆分成城市街道邮编等更具体属性的地址),Derived (衍生的动态的,比如从出生日期衍生来的年龄属性,出生日期在这里属于stored attribute)。
Every entity must have a final primary key: a minimal set of
attributes that can uniquely identity its entity instances.
关键字Key 的类型包括:Super key,Candidate key,Primary key
没有任何关键字的实体叫做 弱实体类型,附属于另一个实体。
基数比例(Cardinality ratio)定义了一个实体的特定实例可以与另一个实体的实例相关的最大次数。
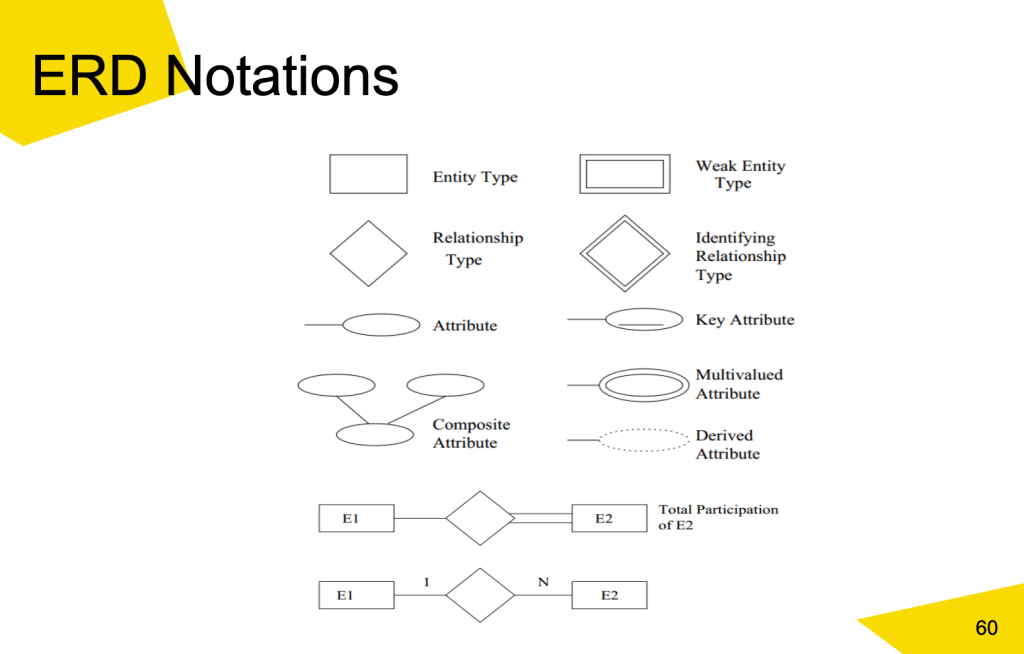
注意 ⚠️ 这些符号的使用并不唯一,在这门课中约定这么用。
全参与(Total Participation)在数据库关系中指的是,某个实体集中的每一个实体都必须参与至少一次该关系。这通常在实体-关系图(ERD)中用双线表示实体与关系之间的连接。举例说明全参与情景:医院数据库
实体和关系:
- 实体 1: Prescription(处方) —— 表示医生开出的处方。
- 实体 2: Patient(患者) —— 表示接受治疗的患者。
- 关系: Prescribed_to(被开给) —— 表示某个处方是开给哪个患者的。
处方在关系 Prescribed_to 中的全参与: - 每个*处方(Prescription)必须与某个患者(Patient)*相关联,因为没有开给患者的处方是没有意义的。
- 在实体-关系图(ERD)中,处方(Prescription)与Prescribed_to关系之间用双线表示。
对比:部分参与(Partial Participation)
为了帮助理解,可以对比一个部分参与的例子:假设还有一个实体Doctor(医生),与*Prescription(处方)之间通过Prescribes(开处方)*关系相连:
- 并非所有医生(Doctor)都会参与到Prescribes关系中(例如有些医生可能不负责开药,或者暂时没有给患者开过处方)。
- 这样的话,并不是每个*医生(Doctor)*都需要参与该关系,这是部分参与。
- 医生(Doctor)与Prescribes之间会用单线表示。
一项重要技能是学会把现实关系转化为 ER图。
关系代数(relational algebra)是 SQL 的理论基础。理解关系代数有助于理解数据库查询优化的原理,从而帮助我们写出效率更高的查询语句。通过优化关系代数表达式,可以减少查询的时间和空间复杂度,提高数据库的性能。
一元关系操作(Unary Relational Operations)
- 从关系(表)中筛选(Select)出满足条件的行( 𝜎<𝑠𝑒𝑙𝑒𝑐𝑡𝑖𝑜𝑛 𝑐𝑜𝑛𝑑𝑖𝑡𝑖𝑜𝑛>(𝑅))
- 从关系中选取(Project)特定的列(𝜋<𝑎𝑡𝑡𝑟𝑖𝑏𝑢𝑡𝑒 𝑙𝑖𝑠𝑡>(𝑅))
集合操作(Operations from Set Theory)
- 合并两个关系,将两者中的所有元组(行)都包含在结果中,去除重复值。并(Union) (A ∪ B)
- 返回两个关系中共有的元组。交(Intersection) (A ∩ B)
- 返回一个关系中存在但另一个关系中不存在的元组。差(Difference) (A − B)
- 笛卡尔积(Cartesian Product)
二元关系操作(Binary Relational Operations)
- 根据条件将两个关系中的元组组合起来。连接(Join ⋈)
- 找出一个关系中与另一个关系的所有元组都相关联的元组。除(Divide ➗)
重命名操作 是关系代数中一个简单但非常实用的工具,用于修改关系名称或属性名称。通过 ρ 来表示,支持对整个关系或部分属性进行重命名。
聚合操作用于对关系中的一组元组执行计算操作,类似于 SQL 中的聚合函数(如 SUM, COUNT, AVG, MIN, MAX)。在关系代数中,聚合操作符(Aggregate Operators)通常用于生成汇总结果,比如统计数量、求和、计算平均值等。聚合操作符的结果可以按某些属性进行分组(Group By),也可以直接计算全表的汇总值。
聚合操作符用 γ(gamma) 表示,形式如下

Week 3 SQL
PL/pgSQL(Procedural Language/PostgreSQL)是 数据库中的一种扩展语言,用于编写存储过程和函数。它将过程化编程的功能引入了 PostgreSQL,使我们可以编写更复杂的数据库操作逻辑。
SQL 虽然强大,但是也有一些局限。用去银行取钱来举例,如果输入的金额大于余额,应该返回余额不足的提示,如果金额足够取钱顺利,那么就返回新的余额。在这个例子里需要使用 SQL 来访问数据库,同时也需要 procedural code 来控制两种假设的情况。
编程语言与数据库管理系统是解耦的。意味着编程语言可以与多种数据库兼容,而数据库可以支持多种编程语言。比如,Python、Java、C++ 等主流编程语言都可以通过相应的数据库驱动与 MySQL、PostgreSQL 等数据库交互,这样应用程序可以在不同的数据库之间迁移。
存储过程(Stored procedures)是写在数据库里的小程序,可以直接在数据库内执行复杂的操作和逻辑,提升了数据库的功能和性能。
Week 4.2 Functional_Dependencies
函数依赖描述了属性之间的关系。如果一个属性(或一组属性)X的值能够唯一确定另一个属性(或一组属性)Y的值,那么就说Y函数依赖于X,记作X → Y。
Armstrong公理系统主要包含以下三个公理:
自反律(Reflexivity)e.g. X → X
增广律(Augmentation)e.g. X → Y ⇒ XZ → YZ
传递律(Transitivity)e.g. X → Y, Y → Z ⇒ X → Z
在关系数据库中,属性闭包(Closure of Attributes)是指给定一组属性和一组函数依赖,通过不断应用函数依赖的推理规则(即Armstrong公理),所能推导出的所有属性的集合。
计算所有候选键 (Compute all Candidate Keys)是数据库设计中一个重要的任务,它有助于我们更好地理解数据之间的关系,并为数据库的规范化提供依据。候选键是关系中一个属性或一组属性的集合。必须满足两个条件:唯一性和最小性。
计算候选键的关键步骤:1 确定关系的属性集和函数依赖集 2 计算属性闭包 3 筛选候选键
具体例子解释: 数据库表 学生课程注册表包含以下属性和函数依赖
关系 R (StudentID, CourseID, InstructorID, Room, Time)
函数依赖(FD):
- StudentID, CourseID→InstructorID, Room, Time
(学生和课程共同决定教师、教室和时间) - InstructorID→Room, Time
(教师决定教室和时间) - Room, Time→InstructorID
(教室和时间决定教师)
计算结果:能覆盖所有属性的是 {StudentID, CourseID}
Week 5.1 Normal Forms
➢ 1NF, 2NF, 3NF (Codd 1972)
在第一范式中,每一列的数据都是原子性的,即每一列只能有单一值,不能包含列表或重复的组。比如电话号码列里有多个电话号码(即一个字段中有多个值)。为了符合1NF,我们需要拆分这些数据。
第二范式要求首先满足1NF,然后表中的非主键列必须完全依赖于主键(对于复合主键,非主键列不能只依赖主键的一部分)。
在第三范式中,表要满足2NF,并且每个非主键列都直接依赖于主键,而不能通过其他非主键列传递依赖于主键。
➢ Boyce-Codd NF (1974)
BCNF是第三范式的加强版本,要求表中所有非主键列都严格依赖于主键。在BCNF中,即使是复合主键的部分依赖情况也会被消除。
➢ Multivalued dependencies and 4NF (Zaniolo 1976 and Fagin 1977)
第四范式在第三范式和BCNF的基础上,进一步规范了表结构,消除多值依赖 (Multivalued Dependency, MVD)。4NF要求一个关系表在满足BCNF的基础上,不存在非平凡的多值依赖。
➢ Join dependencies (Rissanen 1977) and 5NF (Fagin 1979)
在4NF基础上,进一步消除连接依赖,以防止复杂的多对多依赖带来的冗余。适用于三方或更多复杂依赖关系。
这就是数据库范式的几种常见形式,每种范式通过减少依赖和冗余,使数据库结构更为合理,提高数据一致性。4NF和5NF都是高级范式,它们主要用于特殊的数据冗余问题,一般只在数据模型非常复杂的情况下才使用。
Week 5.2 Relational Database Design
在数据库规范化过程中,将关系分解成多个子关系有助于减少数据冗余、避免更新异常以及保持数据的一致性。然而,这种分解可能导致部分依赖关系在分解后的表中无法直接体现,进而影响数据的完整性约束。因此,为了确保数据的正确性,分解时需考虑保持依赖性(Dependency Preservation)。
无损连接性质(Lossless Join Property)的意思是,当我们将一个表分解成多个子表时,这些子表应当能够通过自然连接重新组合成原表,且结果数据与原始数据完全一致。
计算最小覆盖(Computing a Minimal Cover)是在数据库规范化过程中用于简化一组函数依赖的步骤,目的是找出一个等价的依赖集,其中所有依赖都是最简形式。最小覆盖帮助数据库设计者减少冗余,提高查询效率,并确保数据库结构的合理性。
简单总结:
1. 数据冗余会导致更新异常,不利于数据一致性。
2. 规范化可以减少冗余,通常依据函数依赖(FD)来进行。
3. BCNF可以消除所有由函数依赖引起的冗余,但不总能保证依赖保持。
4. 3NF总能找到一个依赖保持且无损的分解,但可能会保留一些冗余。
5. 即使找到一个依赖保持、无损且无冗余的分解,出于效率原因,有时也难以彻底消除冗余。
Week 7 – Disk, File, Index
存储设备分为三个层次,每个层次具有不同的访问速度和成本。主内存访问速度快,但价格较高,用于存储正在被CPU使用的临时数据,以便快速访问。次级存储即硬盘,用于长时间保存数据,当数据不再被频繁使用时存放在这里。访问速度比主内存慢,但成本较低,容量更大。三级存储如磁带、CD等,访问速度最慢,但价格最低,通常用于存储大量的备份数据。
缓冲池(Buffer Pool)是数据库管理系统中的一个关键机制,用于在磁盘和内存之间管理数据的传输。它通过在主内存中维护一个缓冲区来存储从磁盘读取的数据块,从而有效地管理和优化数据访问的速度。
当数据库需要从磁盘读取数据时,首先会在缓冲池中查找。如果数据已经在缓冲池中,则直接从内存中读取,这比从磁盘读取要快得多。如果数据不在缓冲池中,则会从磁盘加载数据块到缓冲池,再将数据返回给请求方。
缓冲池的空间是有限的,当缓冲池已满且需要加载新数据时,系统会按照某种替换策略(如LRU最近最少使用)将不常用的数据块移除,为新数据腾出空间。对于修改过的数据,缓冲池会定期将它们写回磁盘,确保磁盘上的数据保持最新。
Hit Rate 是缓存性能的一个衡量标准,表示从缓存中成功找到所需数据的比例。
Hit rate = #cache hits / (#cache hits + #cache misses)
比率高表示缓存系统在处理请求时更高效,因为大多数请求都能从缓存中找到,无需访问更慢的存储层。
顺序泛洪(Sequential Flooding)是数据库系统或缓存系统中的一种性能问题,发生在LRU缓存替换策略和顺序访问模式同时出现时。它会导致缓存效率下降,从而频繁进行数据的装载和移除,降低系统性能。假设缓存只能容纳10个页面,而系统需要顺序读取100个页面。在LRU策略下,每个新页面会替换最旧的页面,缓存中没有页面被重复访问,等同于没有缓存,所有页面都需要从磁盘中重新加载。
Week 8 Transaction_Management (Part 1, Part 2)
事务(Transaction)是数据库操作的基本单元,用于访问和更新数据项,确保数据的完整性和一致性。在数据库系统中,事务的执行涉及两大主要问题:故障处理和并发执行。
为了解决这两个问题,事务被设计为满足以下ACID性质:原子性Atomicity:事务要么全部完成,要么全部回滚。 一致性Consistency:事务完成后,数据应保持一致。隔离性Isolation:一个事务的操作对其他事务是不可见的,直到事务完成。持久性Durability:事务一旦提交,数据的更新应永久保存。

举例来说,这里有 T1, T2两个事务。T1 表示A转给B五十, T2表示 A把自己余额的百分之十转给B。
假设A和B初始都有一千,如果操作以任意顺序(执行T1 T2的先后顺序)交错执行,可能会导致不正确的结果。 ➢ 通过串行执行事务可以轻松确保隔离性。 问题:为什么不只运行串行调度? 答案:因为由于磁盘延迟,吞吐量会非常差。
可串行化调度(Serializable Schedule)是数据库并发控制中的一个重要概念,用于确保多个事务的并发执行不会破坏数据的一致性。对于一个可能并发执行的调度 S,如果 S 与某个串行调度具有等价性,则称 S 是可串行化的。可串行化的非串行调度与某种串行执行顺序效果相同,保持数据一致性;而不可串行化的非串行调度会导致数据不一致,因此在事务并发控制中要避免这种情况。
Non-serializable 和 Nonserial 区别:
Non-serializable(非可串行化) 是指一个事务调度的执行结果不是一个合法的串行调度。
Nonserial(非串行) 只是指事务调度不是串行的。也就是说,事务没有按照完全的顺序一个接一个执行,而是发生了并发(即事务交替进行)。但是,这个术语并不一定暗示事务调度会导致不正确的结果,只是简单地指并发执行的事实。
Precedence Graph(前置图)是一种用来表示事务之间依赖关系的有向图,通常用于分析数据库事务调度的正确性,特别是在并发控制和事务隔离的上下文中。它通过图中的节点和边来表示事务之间的关系,帮助我们判断事务调度是否是可串行化的。

并发控制技术(Concurrency Control Techniques)是数据库管理系统用来管理多事务并发执行的方式,以保证数据一致性并防止数据冲突。常用的并发控制技术之一是基于锁的控制(Lock-based)。当事务需要访问一个数据项时,必须先获取该数据项的锁;释放锁后,其他事务才可访问此数据项。死锁是一个潜在问题。死锁发生在多个事务之间,它们彼此等待对方释放锁,导致所有事务都无法继续。数据库系统通过死锁检测、预防和恢复机制来缓解死锁,从而实现高效、安全的并发控制。

Two-Phase Locking(2PL,两阶段锁协议)是一种用于并发控制的协议,它确保事务在执行过程中不会因为并发执行而导致数据的不一致。
Wait-for Graph(等待图)是用来描述和分析数据库系统中事务之间死锁(Deadlock)问题的一种图结构。它表示事务之间由于资源(如锁)争用而发生的等待关系。死锁是指一组事务相互等待对方释放资源,导致这些事务无法继续执行,进入一种“无限等待”状态。
在缓存管理和页面替换中,LRU 和 MRU 都是常见的替换策略。它们用于决定当缓冲区已满时,哪一个页面应该被替换。它们的主要区别在于它们如何选择被替换的页面。LRU(Least Recently Used)策略认为最久未被访问的页面最有可能不再被使用,因此将它替换掉。具体来说,LRU 替换策略会替换掉最长时间未被访问的页面。MRU(Most Recently Used)策略则相反,认为最近使用的页面最不可能被再次使用,因此会替换掉最近刚被访问过的页面。MRU 策略的基本思想是:如果一个页面刚刚被使用过,那它在短期内很可能不会再次被访问。
NoSQL 是 “Not Only SQL”的缩写,指的是非关系型数据库,设计上更加灵活,用于存储和处理大规模、结构化或非结构化数据。这种数据库适合于大数据环境下的数据分析和在线查询。
CAP定理在NoSQL中非常重要,它描述分布式数据库系统在一致性(Consistency)可用性(Availability)分区容错性(Partition tolerance)之间的取舍。一个系统在同一时间只能满足其中两个特性,不能三者兼得。这就意味着NoSQL数据库在系统设计中会有所取舍,以应对分布式环境下的不同需求。
OLTP(在线事务处理):用于处理大量简单事务,适用于传统关系型数据库场景,关注事务的完整性和高并发性,例如银行交易。
OLAP(在线分析处理):用于数据分析和复杂查询,适合多维数据模型的数据仓库应用,关注数据聚合和分析性能。
HTAP 混合事务/分析处理是一种新型的数据库设计,支持在线事务和在线分析的混合处理。HTAP数据库能够在同一系统中高效地执行事务处理和分析任务,适用于大规模数据集的实时分析需求。
Neo4j 是当前最流行的图数据库之一,专门用于存储和查询图形数据结构。图数据库以图形模型来表示数据,将数据以节点(Nodes)、关系(Relationships)和属性(Properties)的形式组织起来,非常适合处理具有复杂连接的数据,如社交网络、推荐系统、知识图谱等。
相关课程包括 COMP9312 Data Analytics for Graphs,COMP9313 Big Data Management
更多参考链接 研究团队 https://unswdb.github.io/
数据库文档 https://www.postgresql.org/docs/15/index.html

Leave a comment / 留言会在审核后公开,可备注不公开仅作者可见